
< 목차 >
3. VIP 분석하기
- VIP 고객 정보 파악
- VIP 고객 대출 정보 파악
- VIP 고객들의 예치 현황 파악
< 3. VIP 분석하기 >
< 3-1 VIP 고객 정보 파악 >
# Annual_Income 박스플롯으로 그리기
# x 축 표시 형식을 변경하는 함수 정의
from matplotlib.ticker import FuncFormatter
# x 축 표시 형식을 변경하는 함수 정의
def format_func(x, pos):
return '{:,.0f}'.format(x/1000) # #,### 형식으로 포맷팅
plt.figure(figsize=(16,9))
sns.boxplot(data=customer,x='Annual_Income')
# x 축에 적용할 Formatter 설정
formatter = FuncFormatter(format_func)
plt.gca().xaxis.set_major_formatter(formatter)
# 그래프 표시
plt.xlabel('Annual_Income($1k)')

✔️ '{:,.0f}'.format(x/1000)
x를 천 단위로 나눈 값을 천 단위 구분 기호를 추가하여 포맷팅합니다. 예를 들어, x가 10000일 경우, 10으로 포맷팅됩니다.
✔️plt.gca().xaxis.set_major_formatter(formatter)
이 코드는 현재의 축 객체를 가져와서 x축의 주요 포맷터를 설정합니다. formatter 객체를 사용하여 x축 레이블을 포맷팅합니다
plt.gca(): 현재의 축 객체를 반환합니다
xaxis.set_major_formatter(formatter): x축의 주요 포맷터를 설정합니다.
이 코드를 실행하면 커스텀 포맷터가 적용된 박스플롯이 표시됩니다. x축 값은 천 단위로 나누어지고 천 단위 구분 기호(콤마)가 추가된 형식으로 표시됩니다. 예를 들어, 10000은 10으로 표시됩니다.

Question )
선생님! 질문이 있습니다!!!
박스플롯 그래프를 그릴때 무조건 x축과 y축 컬럼을 지정해줘야 되는것 아닌가요?!
x축만 지정하는 것하고 x축과 y축을 지정하는 것하고 어떤 차이점이 있나요!?!

Answer )
박스플롯은 y축에 값을 지정하지 않으면 자동으로 해당 값의 분포를 기준으로 박스플롯을 생성합니다.
x축에 있는 값들의 분포를 표시하는 것입니다
즉, x축의 Annual_Income의 값들만을 사용하여 그 값들의 분포를 시각화합니다.
✔️ 결론
1. y축에 값을 설정한 경우
y축에 값을 설정하면, x축의 그룹별로 y축 값의 분포를 시각화합니다. 즉, 두 개의 변수를 사용하여 관계를 시각화하게 됩니다. 예를 들어, 특정 그룹(x축)에 따라 y축 값이 어떻게 분포하는지를 보여줍니다.
2. y축에 값을 설정하지 않은 경우
y축에 값을 설정하지 않으면, 단일 변수의 분포를 시각화합니다. 즉, 하나의 열에 있는 값들의 분포를 보여줍니다. 이 경우, y축은 자동으로 값의 범위를 나타내며, x축은 단일 변수를 나타냅니다.
# 연간 수입의 describe() 출력하기
천 단위 구분기호 추가하기
customer['Annual_Income'].describe().apply(lambda x: format(x, ','))

apply() 메서드는 시리즈의 각 요소에 함수를 적용합니다.
여기서 사용된 함수는 lambda x: format(x, ',')입니다.
format(x, ','): 파이썬의 format 함수로, 숫자를 문자열로 변환할 때 천 단위 구분 기호(쉼표)를 추가합니다.
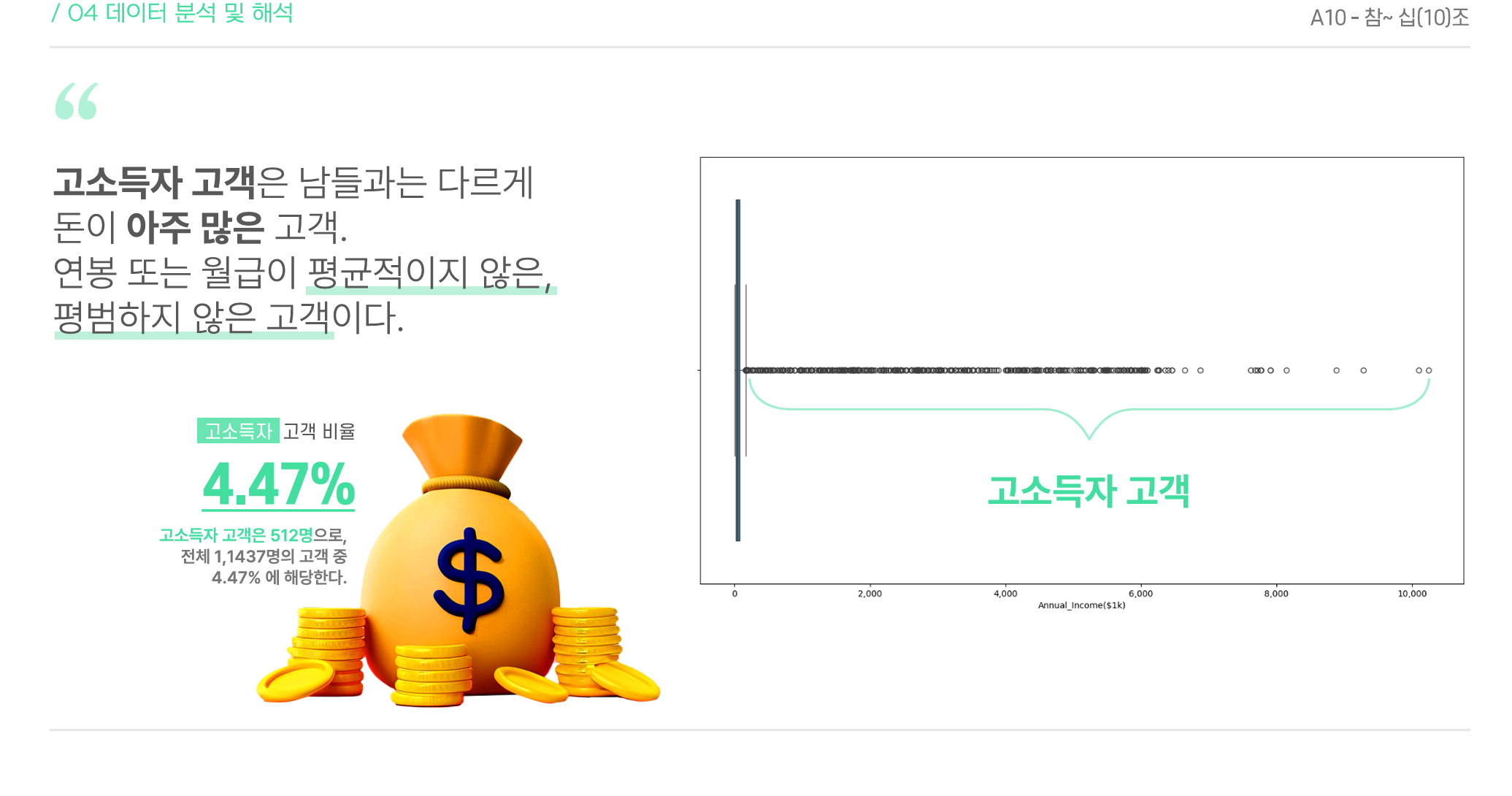
# 이상치 이상인 고소득 회원수 세기
[ 방법1 ] loc 사용하기
# 이상치 직접 계산하기
q1 = customer['Annual_Income'].quantile(0.25)
q3 = customer['Annual_Income'].quantile(0.75)
IQR = q3-q1
upper_bound = q3 + IQR * 1.5
cond = customer['Annual_Income'] >= upper_bound
customer.loc[cond, 'Annual_Income'].count()
[ 결과 ]
512
[ 방법 2 ] 테이블 [불리언] [컬럼]
loc를 사용하지 않고 다음과 같은 형태로도 작성 가능하다!
customer[customer['Annual_Income']>=upper_bound]['Customer_ID'].count()
# 고객 연봉자 테이블 따로 분리하기
high_salary_group2 = customer[cond]
high_salary_group2.describe()

그런데 테이블 자체가 가로로 길어서 읽기가 약간 불편한거 같기도 하다
그렇다면 인덱스와 컬럼을 Change! 해줄수도 있을까?!
✔️일단 숫자형만 가지고 오기
dic = {}
num_cols = high_salary_group.select_dtypes(include=['number']).columns
num_cols
✔️ 숫자형 컬럼에 대해서 agg함수를 이용해 평균값과 중앙값을 계산한 후 딕셔너리 타입으로
for i in num_cols:
dic[i] = list(high_salary_group[i].agg(['mean','median']))
dic

✔️만약 그대로 데이터프레임에 담아서 출력한다면?
데이터프레임에서 인덱스를 지정하지 않는다면 숫자 인덱스인 0,1,2,,, 의 인덱스가 부여된다
df = pd.DataFrame(dic)
df
따라서 각각의 의미를 알려주기 위해 인덱스를 지정한후 (0,1,2,,로 되는것 방지)
출력하였다
df = pd.DataFrame(dic)
df.index = ['mean','median']
df
만약 가로로 컬럼이 너무 길어서 읽기가 힘들다면 T를 통해서 서로의 위치를 바꿀 수 있
df = pd.DataFrame(dic)
df.index = ['mean','median']
df = df.T
df

✔️해당 결과에서 천의 단위마다 , 를 붙이고 소수점 이하 둘째 자리까지 나타내기
# 천단위 구분자 추가
df['mean'] = df['mean'].apply(lambda x: "{:,.2f}".format(x))
df['median'] = df['median'].apply(lambda x: "{:,.2f}".format(x))
df

# Question
포맷 문자열 '{:,.0f}'와 '{:,.2f}' 의 차이점이 무엇인가?
# Answer
:
포맷 시작을 알리는 문자입니다.
,
천 단위 구분 기호(쉼표)를 추가합니다.
.0f
소수점 이하 자릿수를 0으로 설정하여 소수점 이하를 표시하지 않습니다.
.2f
소수점 이하 자릿수를 2로 설정하여 소수점 이하 둘째 자리까지 표시합니다.
1. '{:,.0f}'
'{:,.0f}'
[ 예시 ]
입력 값이 1234567이면, 출력은 1,234입니다 (입력 값은 천으로 나누어지고, 소수점 이하가 제거됨).
format(1234567 / 1000, '{:,.0f}') → 1,234
2. '{:,.2f}'
'{:,.2f}'
[ 예시 ]
입력 값이 1234567이면, 출력은 1,234,567.00입니다.
format(1234567, '{:,.2f}') → 1,234,567.00
# 고소득자의 나이대별 빈도
# 30대 초반(30-35세)의 고객이 88명으로 가장 많다.
sns.histplot(data=high_salary_group,x='Age',
binrange=[10,60], bins=10,
color='green', alpha=0.5)
# 최대 빈도수 계산하기
cond = (high_salary_group['Age']<35) & (high_salary_group['Age']>=30)
max_cnt = high_salary_group.loc[cond,'Age'].count()
plt.text(31.5, 100, max_cnt)
plt.ylim(0,110)
plt.title('Age Distribution of High Salary Group')

# vip고객과 아닌 고객의 연체일 박스플
customer['salary_group'] = ['VIP' if income > upper_bound else 'else' for income in customer['Annual_Income']]
sns.boxplot(data=customer, x='salary_group', y='Delay_from_due_date', palette = ['#22CC88','#EEEEEE'])
plt.title('Delay from Due Date by Salary Group')

< 3-2 VIP 고객 대출 정보 파악 >
# VIP 고객들은 어떤 대출 상품을 많이 이용하는지, 대출의 개수(num_of_loan)은 몇개인지
# VIP 고객들은 어떤 대출 상품을 많이 이용하는지, 대출의 개수(num_of_loan)은 몇개인지, VIP 고객들의 대출 액수는 얼마인지, 채무를 잘 갚고 있는지 확인해보자.
customer2 = customer.copy()
loan_grouped = customer2.groupby('salary_group').sum().iloc[:,16:25]
loan_grouped = loan_grouped.T
loan_grouped
컬럼명으로 일일이 지정하는 것보다 집계함수를 먼저 사용한후 iloc로 인덱스 접근하면 더 편리하다
또한 가로축으로 너무 길다면 T를 통해서 인덱스와 컬럼을 바꿔주자

loan_grouped['VIP']
loan_grouped
# Loan Types of High Salary Group
# Loan Types of High Salary Group
palette = ['#EEEEEE','#EEEEEE','#EEEEEE','#EEEEEE','#EEEEEE','#EEEEEE','#EEEEEE','#22CC88','#B9FFE3']
explode = [0.01,0.01,0.01,0.01,0.01,0.01,0.01,0.01,0.01]
plt.figure(figsize=(16,9))
plt.pie(loan_grouped['VIP'],
startangle=20,
explode=explode,
colors = palette, autopct='%1.2f%%',)
plt.legend(loan_grouped.index,bbox_to_anchor=(1, 0.5))
plt.title('Loan Types of High Salary Group')
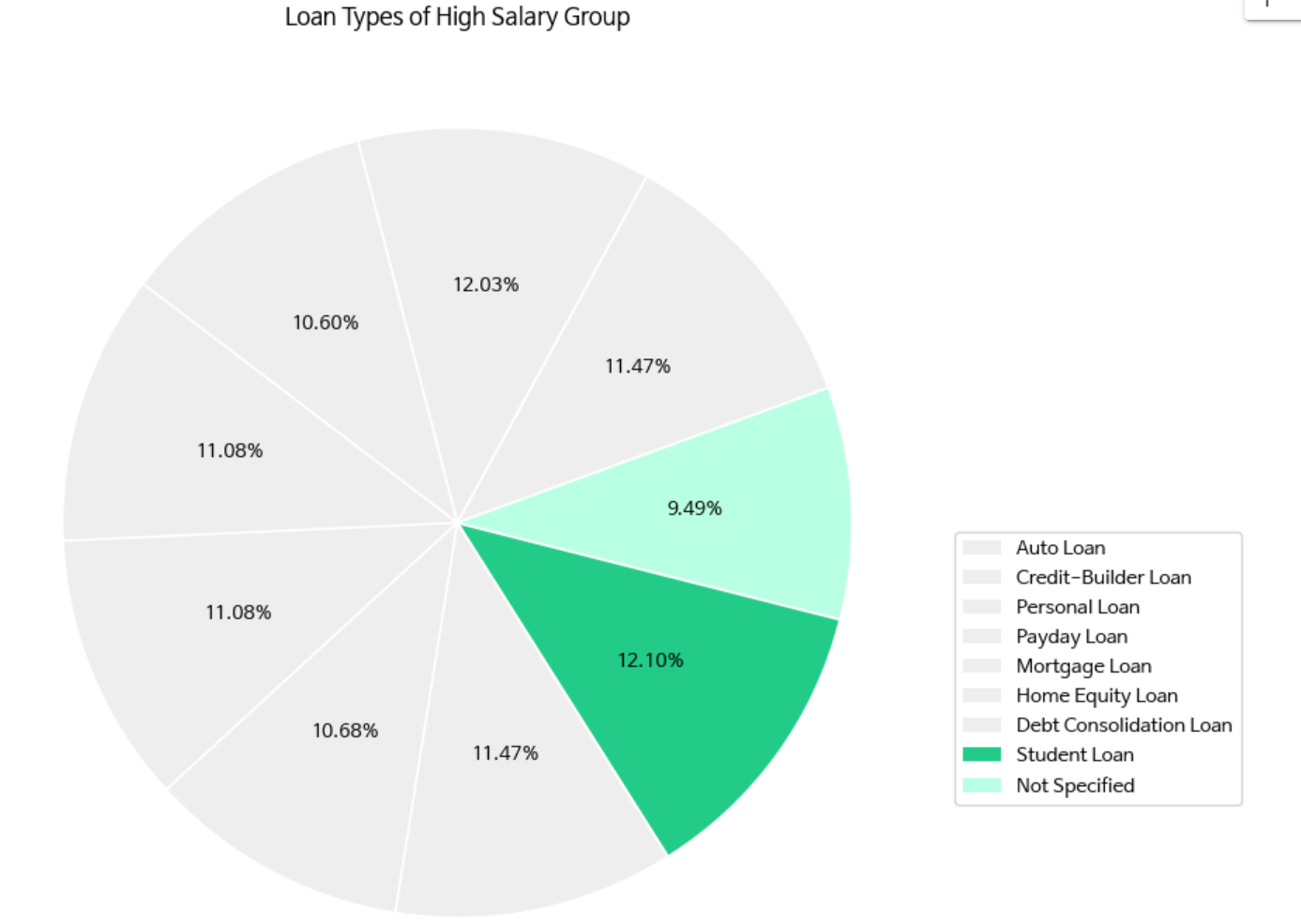
< 코드 설명 >
✔️palette: 파이 차트의 각 조각에 대한 색상을 지정하는 리스트입니다.
#EEEEEE: 회색 계열의 색상.
#22CC88: 녹색 계열의 색상.
#B9FFE3: 밝은 녹색 계열의 색상.
✔️explode: 각 파이 조각을 중심에서 약간 떨어뜨리는 설정입니다.
0.01: 각 조각을 중심에서 0.01만큼 떨어뜨립니다. 이 값이 클수록 조각이 더 멀리 떨어집니다.
✔️figsize: 그래프의 크기를 설정합니다.
figsize=(16,9): 가로 16인치, 세로 9인치 크기의 그래프를 생성합니다.
✔️plt.pie(): 파이 차트를 생성하는 함수입니다.
loan_grouped['VIP']: 파이 차트를 그릴 데이터. 각 대출 유형의 비율을 나타냅니다.
startangle=20: 첫 번째 파이 조각의 시작 각도를 설정합니다. 20도로 설정하여 첫 조각이 약간 기울어진 상태에서 시작합니다.
explode=explode: 각 조각을 중심에서 떨어뜨리는 설정을 적용합니다.
colors=palette: 지정된 색상 팔레트를 사용하여 파이 조각의 색상을 설정합니다.
autopct='%1.2f%%': 각 조각에 비율을 소수점 둘째 자리까지 표시합니다. 예: 12.34%
✔️plt.legend(): 파이 차트의 범례를 추가합니다.
✔️loan_grouped.index: 범례 항목의 이름을 대출 유형으로 설정합니다.
bbox_to_anchor=(1, 0.5): 범례의 위치를 그래프 밖 오른쪽 중간에 배치합니다.
# 소득별 나이대별 대출 현황
# 소득별 나이대별 대출 현황
loans = ['Auto Loan', 'Credit-Builder Loan','Personal Loan','Payday Loan','Mortgage Loan','Home Equity Loan','Debt Consolidation Loan','Student Loan', 'Not Specified']
customer.groupby(['salary_group','age_group'])[loans].sum()

# vip 그룹의 연령대별 대출 정보
customer['salary_group']

# vip그룹의 연령대별 대출 정보
vip_age_loantype = customer.groupby(['salary_group','age_group'])[loans].sum().iloc[0:5]
vip_age_loantype
vip_age_loantype = vip_age_loantype.reset_index().drop(['salary_group','age_group'],axis=1).T
vip_age_loantype

vip_age_loantype.columns = [10,20,30,40,50]
vip_age_loantype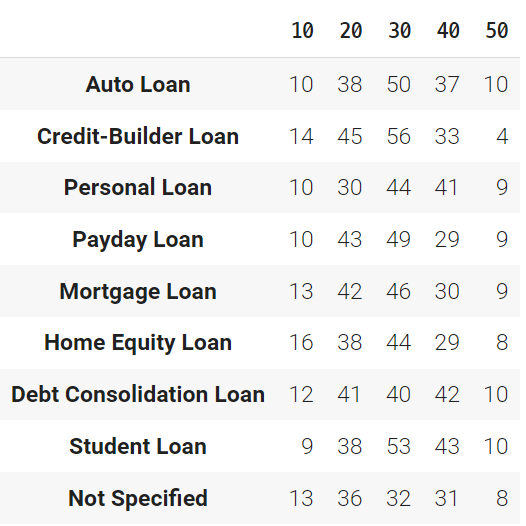
# VIP 고객 중에서 미상환 채무가 가장 적은 연령대를 분석
# → VIP 고객중 미상환 채무가 가장 적은 그룹은 30대(783.975, 1위), 40대(820.020, 2위), 50대(849.690,3위)
stat = investment_stat[investment_stat['salary_group']=='VIP']
green_palette2 = ['#22CC88','#43DFA0','#78ECBD','#B9FFE3','#EFFBF7']
# 'salary_group'의 median 값을 기준으로 정렬된 순서를 생성합니다.
median_order = stat.groupby('age_group')['Outstanding_Debt'].median().sort_values().index
# median 값에 따라 정렬된 순서로 boxplot을 그립니다.
sns.boxplot(data=stat, x='age_group', y='Outstanding_Debt', palette=green_palette2, order=median_order)

코드 설명
✔️median_order = stat.groupby('age_group')['Outstanding_Debt'].median().sort_values().index
stat.groupby('age_group'): 'age_group'(연령대)별로 데이터를 그룹화합니다.
.sort_values(): 중앙값을 기준으로 정렬합니다.
.index: 정렬된 인덱스를 가져옵니다. 이는 정렬된 연령대의 리스트입니다.
이 단계에서는 각 연령대별 미상환 채무의 중앙값을 계산하고, 중앙값을 기준으로 연령대를 정렬합니다. 예를 들어, 미상환 채무 중앙값이 작은 연령대부터 큰 연령대 순으로 정렬됩니다.
✔️order=median_order: 연령대를 중앙값 기준으로 정렬된 순서대로 표시합니다
< 3-3 VIP 고객들의 예치 현황 파악 >
# VIP 고객들의 월 소득과 월 투자의 회귀분석
# VIP 고객들은 은행
# 월 소득과 월 투자의 회귀분석 - VIP
plt.figure(figsize=(16,9))
stat = investment_stat[investment_stat['salary_group']=='VIP']
sns.scatterplot(data = stat, x='Monthly_Income', y='Amount_invested_monthly', hue = 'age_group', palette = green_palette2, alpha= 0.5)
plt.title('Regression Analysis of Monthly Income - Amount of Monthly Investment(VIP)')
grouped = stat.groupby('age_group')
grouped

< 코드 설명 >
✅sns.scatterplot() 함수를 사용하여 산점도를 그립니다.
✅data=stat : 데이터로는 VIP 고객들의 데이터를 사용합니다.
✅x='Monthly_Income', y='Amount_invested_monthly' : x축과 y축에는 각각 월 소득과 월 투자 금액을 사용합니다.
✅hue='age_group' : 연령대별로 다른 색상을 지정하여 구분합니다.
✅palette=green_palette2 : 색상 팔레트를 설정합니다.
✅alpha=0.5 : 점의 투명도를 설정합니다.
연령대별로 그룹화된 데이터를 반복문을 통해 순회합니다.
✅np.polyfit() 함수를 사용하여 각 그룹에 대한 선형 회귀분석을 수행합니다. 이를 통해 회귀선의 기울기와 절편을 계산합니다.
✅plt.text() 함수를 사용하여 각 그룹에 대한 회귀선의 방정식을 그래프에 표시합니다.
# 일반 고객 회귀분석
# 일반 고객 회귀분석
plt.figure(figsize=(16,9))
green_palette2 = ['#22CC88','#43DFA0','#78ECBD','#B9FFE3','#EFFBF7']
stat = investment_stat[investment_stat['salary_group']=='else']
sns.scatterplot(data = stat, x='Monthly_Income', y='Amount_invested_monthly', hue = 'age_group', palette = green_palette2, alpha= 0.5)
plt.title('Regression Analysis of Monthly Income - Amount of Monthly Investment(else)')
grouped = stat.groupby('age_group')
for age_group, group_data in grouped:
z = np.polyfit(group_data['Monthly_Income'], group_data['Amount_invested_monthly'], 1)
slope = round(z[0], 4)
intercept = round(z[1], 2)
plt.text(2500, 1300 - age_group*5, f"For age_group {age_group}: y = {slope}x + {intercept}")

# Credit이 가장 좋은 것에 대해서 히트맵 분석
# → Credit이 가장 좋은 것은 대체로
green_as_cmp = sns.color_palette("light:#22CC88", as_cmap=True)
age_credit = high_salary_group[['age_group','Credit_Mix']]
pivot_age_credit = pd.pivot_table(age_credit,index='age_group', columns='Credit_Mix',aggfunc='size', fill_value=0)
sns.heatmap(pivot_age_credit, cmap='GnBu',annot = True, linewidth= 0.5)
plt.title('Credit By Age Group')

✅aggfunc='size'는 피벗 테이블을 생성할 때 각 그룹에 대한 크기(개수)를 계산하는 방법을 지정하는 인자입니다. 여기서는 각 셀에 해당하는 값의 개수를 나타내도록 설정되어 있습니다.
< 최종 결론 >









< 프로젝트를 하면서 느낀 소감 >

이번 프로젝트를 하면서 가장 중요했던 부분은 무작정 데이터분석을 하고 나서 이런 정보를 알 수 있었다로 끝나는 것이 아니라, 어떤 문제를 해결하기 위하여, 어떤 기업에게 이득을 안겨주기 위해서 등 먼저 목표설정을 한 후 그에 맞는 데이터셋을 사용하여 데이터분석을 한 후 결론을 이끌어내는것이었다.
제한된 데이터의 양 중에서 데이터의 값이 NaN값이라고 해서 무작정 데이터를 삭제하기보다는, 의미있는 값으로 대체하면서 데이터의 양을 보존하면서 데이터분석을 하려고 노력했던 것 같다
또한 문자열 값과 숫자형 값이 있을때, 무작정 어떤 경우에 어떤 값으로 대체해야 하는 것이 아니라 컬럼이 어떤 것을 의미하는지 맥락을 보고 결측값을 채워넣는다면 어떤값을 채워넣어야 하는지, 평균값을 채워넣어야 하는지 최빈값을 채워넣어야 하는지 그 이외의 값을 채워넣어야 하는지 근거가 있어야 하는 것 같다
※ 만약 그래프에서 한글이 깨질때
plt.rcParams['font.family'] ='Malgun Gothic'
plt.rcParams['axes.unicode_minus'] =False
# Reference
https://jaeworld.github.io/visualization/DateFormatter/
(Matplotlib) DateFormatter 사용하여 날짜 포맷팅하기
DateFormatter 사용하여 날짜 포맷팅하기Matplotlib. Seaborn으로 x축이 datetime 타입인 시계열 그래프를 그릴때, 원하는 날짜 포맷으로 표기하기 위해서는 추가 작업이 필요하다. 이때 DateFormatter을 사용하
jaeworld.github.io
'Project⚡️ > Team Project' 카테고리의 다른 글
| [Final 데이터 분석] 쿼리문 정리⚡️ (0) | 2024.07.28 |
|---|---|
| [Pandas] 은행 고객데이터를 이용한 서비스 분석 회고록2 (0) | 2024.05.27 |
| [Pandas] 은행 고객데이터를 이용한 서비스 분석 회고록 (0) | 2024.05.26 |
| [Pandas] 은행 고객데이터를 이용한 서비스 분석 (0) | 2024.05.20 |
| [SQL] 서울시 내에 있는 따릉이 데이터 SQL (0) | 2024.04.16 |