
< 데이터 분석 및 해석 >
1. 기초통계량 분석
2. 그래프 그리기
- 나이대별 정보 수집하기
- 직업별 정보 수집하기
- 상관관계 분석하기
3. VIP 분석하기
- VIP 고객
- VIP
< 1. 기초통계량 분석 >
☑️ Pivot Table()
데이터를 재구성하여 요약, 집계된 정보를 보여주는 테이블 형태
pivot_table() 함수는 데이터프레임에서 피벗 테이블을 생성하는 데 사용됩니다.
주어진 데이터를 사용자가 원하는 형태로 재배치하여 요약된 정보를 보기 쉽게 제공합니다.
[ 피벗 테이블 생성하기 1 ]
index : 인덱스
values : 값
columns : 컬럼
aggfunc : 연산할 함수, 기본값은 mean 이다
import pandas as pd
# 샘플 데이터프레임 생성
data = {
'Date': ['2023-01-01', '2023-01-01', '2023-01-02', '2023-01-02', '2023-01-01'],
'Category': ['A', 'B', 'A', 'B', 'A'],
'Value': [10, 20, 30, 40, 50]
}
df = pd.DataFrame(data)
# 피벗 테이블 생성: 날짜를 행 인덱스로, 카테고리를 열 인덱스로, 값은 'Value'의 합으로 집계
pivot = df.pivot_table(index='Date', columns='Category', values='Value', aggfunc='sum')
print(pivot)
[ 결과1 ]

[ 피벗 테이블 생성하기 2 ]
index : 인덱스
values : 컬
data : 데이터
lst = ['Annual_Income', 'Delay_from_due_date','Num_of_Delayed_Payment', 'Outstanding_Debt', 'Credit_Utilization_Ratio',
'Total_EMI_per_month', 'Monthly_Balance','Amount_invested_monthly', 'Num_of_Loan']
df_pivot = pd.pivot_table(data=customer, index='age_group', values=lst)
df_pivot
[ 결과2 ]

< 2. seaborn 그래프 그리기 >
# 데이터 유형에 따른 seaborn 그래프 구분
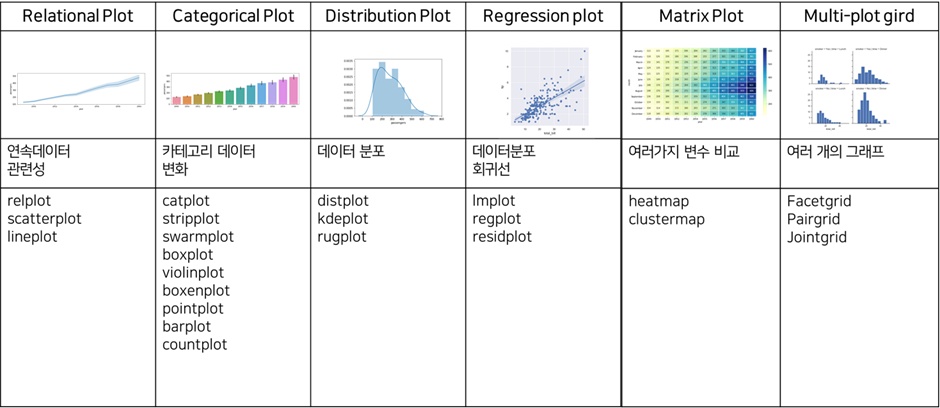
|
그래프 유형
|
함수 |
자료 유형
|
특징
|
|
Line Plot
|
sns.lineplot |
연속형 데이터
|
데이터의 변화 및 추이를 시각화
|
|
Bar Plot
|
sns.barplot |
범주형 데이터
|
카테고리 별 값의 크기를 시각적으로 비교
|
|
Histogram
|
sns.histplot |
연속형 데이터
|
데이터 분포, 빈도, 패턴 등을 이해
|
|
Box Plot
|
sns.boxplot |
연속형 데이터의 분포
|
중앙값, 사분위수, 최소값, 최대값, 이상치 확인
|
|
Scatter Plot
|
sns.scatterplot |
두 변수 간 관계
|
변수 간의 관계, 군집, 이상치 등 확인
|
# 기본 변수값 설명
data=customer,
사용할 데이터셋을 정의합니다
x='Occupation'
x축에 들어갈 컬럼
y='Annual_Income'
y축에 들어갈 컬럼
palette='husl'
예쁜 색깔!
err_kws={'linewidth': 0}
에러바의 선이 그려지지 않게 합니다
< 2-1 나이대별 정보 수집하기 >
# 나이대별 연간소득 - 소득
ax = sns.barplot(data=customer, x='age_group', y = 'Annual_Income', palette='husl', err_kws={'linewidth': 0})
ax.set_title('나이대별 연간 소득', fontsize=20)

# 나이대별 연간 소득 디테일하게 조사하기
grouped = customer.groupby('age_group')['Annual_Income'].mean().round(2)
grouped = grouped.sort_values(ascending=False)
grouped

# 나이대별 회원수 구하기
집계함수를 써서 나온 결과값을 사용
그리고 원래 그룹바이로 묶었던 인덱스를 컬럼으로서 사용하기 위해 reset_index()를 사용하였다
# 그룹별 카운트를 데이터프레임으로 변환
grouped = customer.groupby('age_group')['Customer_ID'].count().reset_index()
# Seaborn을 사용하여 막대 그래프 그리기
ax = sns.barplot(data=grouped, x='age_group', y='Customer_ID', palette='husl')
ax.set_title("나이대별 회원수", fontsize = 20)
# 그래프를 출력합니다.
plt.show()

# 나이대별 미지불 채무 구하기
# 나이대별 미지불 채무 - 대출
ax = sns.barplot(data=customer, x='age_group', y = 'Outstanding_Debt', palette='husl', err_kws={'linewidth': 0})
ax.set_title("나이대별 미지불 채무", fontsize=20)
plt.ylim(500,2000)
plt.ylim( 범위, 범위 ) 함수를 사용했을때 그래프에서의 y축의 범위를 나타낼 수 있다
대신 해당값 안에서의 범위만을 나타내므로 전체 그래프값을 나타내지 못할 수도 있다

< 2-2 직업별 정보 수집하기 >
# < 직업별 연간소득 >
# 그래프 크기 설정
plt.figure(figsize=(12, 6))
# seaborn을 이용한 바 그래프 그리기
ax = sns.barplot(data=customer, x='Occupation', y='Annual_Income', palette='husl', err_kws={'linewidth': 0})
# x 축 눈금 간격 조정
plt.xticks(rotation=45, ha='right') # 글자를 45도 기울이고 오른쪽 정렬로 설정
# 그래프에 제목 추가
ax.set_title('직업별 연간 소득', fontsize=20)
plt.show()

# 직업별 월간 계좌 잔액 구하기
# < 직업별 월간 계좌 잔액 >
# 그래프 크기 설정
plt.figure(figsize=(12, 6))
# seaborn을 이용한 바 그래프 그리기
ax = sns.barplot(data=customer, x='Occupation', y='Monthly_Balance', palette='husl', err_kws={'linewidth': 0})
# x 축 눈금 간격 조정
plt.xticks(rotation=45, ha='right') # 글자를 45도 기울이고 오른쪽 정렬로 설정
plt.ylim(380, 430)
# 그래프에 제목 추가
ax.set_title('직업별 월간 계좌 잔액', fontsize=20)
plt.show()

# 나이와 연간소득의 박스플롯
sns.boxplot(data=customer, x='age_group', y = 'Annual_Income', palette='husl')
plt.ylim(0,250000)
ylim으로 0부터 250000까지만 잘라서 나오게 해서 그위에 값은 안보임

그렇다면 원래의 통계값에서 이상치를 포함한 최대값은 어떻게 나올까?
result = customer.groupby('age_group')['Annual_Income'].describe()
pd.options.display.float_format = '{:.2f}'.format # 결과값을 10의 배수인 정수형태로 볼 수 있게 한다
result
pd.options.display.float_format = '{:.2f}'.format
결과값을 10의 배수인 정수형태로 볼 수 있게 한다

다음 값들은 모두 이상치이고 박스플롯에서 표시된다면 사각형의 직선 밖에서 . 점으로 표시될 것이다
그러나 ylim()을 사용하지 않는다면 박스플롯의 형태가 보이지 않을 것이므로 (이상값이 너무 크다)
ylim()을 통해서 범위를 좁혀서 박스플롯의 형태로 보게 하였다
# 직업과 연간소득의 통계분석
plt.figure(figsize=(12,6))
ax = sns.boxplot(data=customer, x='Occupation', y='Annual_Income', palette='husl')
# x 축 눈금 간격 조정
plt.xticks(rotation=45, ha='right') # 글자를 45도 기울이고 오른쪽 정렬로 설정
# 그래프에 제목 추가
ax.set_title('직업과 연간소득의 통계분석', fontsize=20)
# y 축 범위 설정
plt.ylim(0, 250000)
plt.show()

< 2-3 상관관계 분석하기 >
# 히트맵 분석하기
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
# 수치형 열만 선택
numeric_columns = customer.select_dtypes(include=['float64', 'int64']).columns
# 선택한 열들로 새로운 데이터프레임 생성
customer_numeric = customer[numeric_columns]
# 상관 관계 행렬 계산
corr_matrix = customer_numeric.corr()
# 히트맵 그리기
plt.figure(figsize=(12, 10))
sns.heatmap(corr_matrix, annot=True, fmt=".2f", cmap='GnBu', linewidths=0.5)
plt.title('Correlation Matrix of Customer Data')
plt.show()
[ 결과 ]


# 상관관계 해석 시 유의사항
- 상관 관계가 인과 관계는 아니다 높은 상관 관계가 반드시 인과 관계를 의미하지 않습니다. 예를 들어, 두 변수가 모두 다른 요인에 의해 영향을 받을 수 있습니다.
- 상관 계수의 크기 절대 값이 0.3 이하인 경우는 약한 상관 관계를 나타내고, 0.3에서 0.7 사이는 중간 정도, 0.7 이상은 강한 상관 관계를 나타냅니다.
# Age별 평균값과 중앙값
groupby 이어서 agg 리스트를 이용하여 여러개의 집계함수를 사용하였다!
grouped = customer.groupby('age_group')['Credit_History_Age'].agg(['mean', 'median'])
grouped

# Reference
https://archivenyc.tistory.com/88?category=1184232
[데이터 시각화] 파이썬으로 그래프 그리기 : seaborn (1) 기본 그래프
240516 Today I Learn💡 Seaborn 시각화를 위한 파이썬 라이브러리 중 하나로, matplotlib을 기반으로 하는 데이터 시각화 라이브러리이다. 데이터 유형에 따른 Seaborn 라이브러리 구분 그래프 유형함수
archivenyc.tistory.com
'Project⚡️ > Team Project' 카테고리의 다른 글
| [Final 데이터 분석] 쿼리문 정리⚡️ (0) | 2024.07.28 |
|---|---|
| [Pandas] 은행 고객데이터를 이용한 서비스 분석 회고록3 및 소감문 (0) | 2024.05.27 |
| [Pandas] 은행 고객데이터를 이용한 서비스 분석 회고록 (0) | 2024.05.26 |
| [Pandas] 은행 고객데이터를 이용한 서비스 분석 (0) | 2024.05.20 |
| [SQL] 서울시 내에 있는 따릉이 데이터 SQL (0) | 2024.04.16 |